KREATYWNI
Więcej o nas ... Z NATURY
NASZA OFERTA
co robimy ?
Od momentu założenia w 2004 roku, rozwija się bardzo dynamicznie. Dzięki ciągłemu rozszerzaniu świadczonych przez nas usług, stale powiększamy grupę zadowolonych klientów. To co przekonało naszych klientów to nasza elastyczność i uwzględnianie ich indywidualnych potrzeb.



PORTFOLIO
Nasze prace
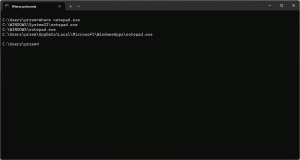
Komenda „where” w systemie Windows służy do lokalizowania plików wykonywalnych w ścieżkach systemowych. Umożliwia użytkownikowi szybkie odnalezienie, gdzie zainstalowane są konkretne programy, co jest szczególnie przydatne w przypadku, gdy w systemie zainstalowanych jest wiele wersji tego samego oprogramowania.
where [opcje] [nazwa_pliku]
| Parametr | Opis |
|---|---|
| nazwa_pliku | Nazwa pliku lub programu, którego lokalizację chcemy znaleźć. |
| /R | Przeszukuje folder i jego podfoldery. |
| /Q | Nie wyświetla wyników, tylko zwraca kod wyjścia. |
| /F | Przeszukuje nazwy plików oraz ich zawartość. |
where notepad.exe
Wykonanie tej komendy pozwala na zlokalizowanie ścieżki do pliku wykonywalnego Notatnika w systemie Windows. Użytkownik otrzyma pełną ścieżkę, w której znajduje się plik „notepad.exe”, co ułatwia uruchamianie programu z poziomu wiersza poleceń.
where /R C:\ myfile.txt
Ta komenda przeszukuje cały dysk C:\ oraz jego podfoldery w poszukiwaniu pliku „myfile.txt”. Dzięki opcji /R, użytkownik może znaleźć plik, niezależnie od tego, w którym katalogu został zapisany, co jest szczególnie przydatne w przypadku dużych struktur folderów.
Komenda „whoami” jest używana w systemach operacyjnych Windows do wyświetlania nazwy aktualnie zalogowanego użytkownika. To proste narzędzie pozwala na szybkie sprawdzenie, pod jakim kontem użytkownik jest aktualnie zalogowany, co jest szczególnie przydatne w środowiskach, gdzie wielu użytkowników może korzystać z tego samego systemu.
whoami [opcje]
| Parametr | Opis |
|---|---|
| /user | Wyświetla nazwę konta użytkownika oraz identyfikator SID (Security Identifier). |
| /groups | Wyświetla grupy, do których należy aktualnie zalogowany użytkownik. |
| /priv | Wyświetla uprawnienia (privileges) przydzielone do konta użytkownika. |
| /all | Wyświetla wszystkie dostępne informacje o użytkowniku, w tym SID, grupy i uprawnienia. |
whoami
Wykonując powyższą komendę w wierszu poleceń, użytkownik otrzyma tylko swoją nazwę użytkownika. Jest to najbardziej podstawowe użycie komendy, które szybko pozwala zidentyfikować, na jakie konto jest aktualnie zalogowany.
whoami /user
Użycie parametru „/user” zwróci nazwę konta oraz jego identyfikator SID. To przydatne w sytuacjach, gdy potrzebujemy informacji na temat bezpieczeństwa konta użytkownika.
whoami /groups
Ta komenda wyświetli wszystkie grupy, do których należy aktualnie zalogowany użytkownik. Jest to bardzo użyteczne, gdy chcemy sprawdzić, jakie uprawnienia i zasoby są dostępne dla danego konta.
whoami /priv
Wykonanie tej komendy pokaże listę uprawnień przypisanych do konta użytkownika. Dzięki temu można łatwo zweryfikować, jakie dodatkowe możliwości ma użytkownik w systemie.
whoami /all
Parametr „/all” umożliwia uzyskanie wszystkich informacji o zalogowanym użytkowniku, łącznie z SID, grupami oraz przydzielonymi uprawnieniami. To kompendium wiedzy o stanie konta użytkownika w danym systemie.
Komenda winnt jest używana w systemach operacyjnych Windows do instalacji systemu Windows z wiersza poleceń. Umożliwia ona tworzenie nośników instalacyjnych oraz zainstalowanie systemu na dysku twardym lub innym nośniku. Jest to jedna z kluczowych komend w procesie instalacji systemu, szczególnie w środowiskach serwerowych oraz w przypadku automatyzacji instalacji.
winnt [opcje] [źródło] [cel]
| Parametr | Opis |
|---|---|
| /s:<źródło> | Określa ścieżkę do źródła plików instalacyjnych, np. z folderu na serwerze. |
| /d: | Określa lokalizację, gdzie ma zostać zainstalowany system Windows. |
| /u | Uruchamia instalację w trybie cichym (bez interakcji z użytkownikiem). |
| /t: | Określa czas w sekundach, po którym instalacja ma się rozpocząć. |
| /noreboot | Zapobiega automatycznemu restartowi po zakończeniu instalacji. |
winnt /s:D:\Instalacja /d:C:\NowySystem /u
W powyższym przykładzie komenda winnt zostanie użyta do zainstalowania systemu Windows z folderu instalacyjnego znajdującego się na dysku D: (D:\Instalacja) do lokalizacji C:\NowySystem. Instalacja odbędzie się w trybie cichym, co oznacza, że nie będzie wymagała interakcji ze strony użytkownika.
winnt /s:\\serwer\udostępniony_folder /d:C:\System /t:60
W tym przypadku komenda winnt zainstaluje system Windows z udostępnionego folderu na serwerze. Instalacja rozpocznie się po 60 sekundach. Jest to przydatne, gdy chcemy zainstalować system na wielu komputerach, dając użytkownikom czas na przygotowanie się do instalacji.
winnt32 to narzędzie używane w systemach operacyjnych Windows, które umożliwia instalację systemu Windows z poziomu istniejącego systemu operacyjnego. Umożliwia ona także aktualizację starszych wersji systemu Windows oraz tworzenie bootowalnych nośników instalacyjnych. Narzędzie to jest szczególnie przydatne w przypadku, gdy użytkownik chce zainstalować system na nowym dysku twardym lub zaktualizować system na istniejącym komputerze.
winnt32 [/s:<ścieżka do źródłowych plików] [/unattended] [/upgrade] [/m:
| Parametr | Opis |
|---|---|
| /s:<ścieżka do źródłowych plików> | Określa lokalizację plików źródłowych instalacji systemu Windows. |
| /unattended | Uruchamia instalację w trybie bezinterwencyjnym, co oznacza, że nie wymaga interakcji ze strony użytkownika. |
| /upgrade | Używane do aktualizacji istniejącego systemu Windows do nowszej wersji. |
| /m: | Określa folder, w którym znajdują się pliki instalacyjne. |
| /d: | Umożliwia określenie, w którym katalogu mają być zainstalowane pliki systemowe. |
| /r | Wymusza ponowne uruchomienie komputera po zakończeniu instalacji. |
| /noreboot | Zapobiega automatycznemu ponownemu uruchomieniu komputera po zakończeniu instalacji. |
winnt32 /s:D:\WinXP /unattended
W powyższym przykładzie komenda winnt32 uruchamia instalację systemu Windows XP z lokalizacji D:\WinXP w trybie bezinterwencyjnym. Użytkownik nie będzie musiał interweniować w trakcie procesu instalacji, co jest przydatne w sytuacjach, gdy konieczne jest zautomatyzowanie procesu, na przykład w przypadku instalacji na wielu komputerach.
winnt32 /upgrade
Ten przykład przedstawia użycie parametru /upgrade, który pozwala na aktualizację już zainstalowanego systemu Windows do nowszej wersji. Użytkownik musi upewnić się, że nowa wersja jest dostępna w lokalizacji, z której uruchamiana jest komenda.
Winrs (Windows Remote Shell) to narzędzie do zdalnego uruchamiania poleceń na komputerach z systemem Windows. Umożliwia administratorom systemów i użytkownikom z odpowiednimi uprawnieniami wykonywanie skryptów oraz poleceń na zdalnych maszynach w sieci. Winrs korzysta z protokołu WS-Management, co pozwala na bezpieczne i efektywne zarządzanie zdalnymi systemami bez konieczności logowania się na nie bezpośrednio.
winrs [opcje]
| Parametr | Opis |
|---|---|
| /r: | Określa adres IP lub nazwę hosta zdalnego komputera. |
| /u: | Specyfikuje nazwę użytkownika z uprawnieniami do logowania na zdalnym komputerze. |
| /p: | Podaje hasło użytkownika (może być pominięte, w takim przypadku użytkownik zostanie poproszony o jego wprowadzenie). |
| /d: | Określa domenę, do której należy użytkownik logujący się na zdalnym komputerze. |
| /t: | Określa maksymalny czas oczekiwania na odpowiedź od zdalnego hosta (domyślnie 30 sekund). |
| /s | Umożliwia uruchomienie polecenia w trybie interaktywnym. |
| /h | Wyświetla pomoc dotyczącą użycia winrs. |
winrs /r:192.168.1.10 /u:administrator /p:mojeHaslo ipconfig
W tym przykładzie polecenie 'ipconfig’ jest uruchamiane na zdalnym komputerze o adresie IP 192.168.1.10. Użytkownik 'administrator’ loguje się za pomocą podanego hasła. Polecenie to zwraca konfigurację sieciową zdalnego komputera, co jest przydatne do diagnozowania problemów z siecią.
winrs /r:serwer1 /u:admin /p:hasloDir /t:60 dir C:\
W tym przykładzie polecenie 'dir C:\’ jest używane do wyświetlenia zawartości katalogu głównego dysku C: na zdalnym serwerze 'serwer1′. Ustalony czas oczekiwania na odpowiedź wynosi 60 sekund. Umożliwia to administratorowi weryfikację plików i folderów na zdalnej maszynie.
Komenda winsat mem jest narzędziem diagnostycznym w systemie Windows, które pozwala na ocenę wydajności pamięci RAM. Używając tej komendy, użytkownicy mogą przeprowadzić testy pamięci, które mogą pomóc w identyfikacji problemów z pamięcią, takich jak niska wydajność czy błędy w działaniu systemu. Wyniki testu mogą być użyteczne przy optymalizacji ustawień systemowych oraz przy podejmowaniu decyzji dotyczących zakupu dodatkowej pamięci RAM.
winsat mem [opcja]
| Parametr | Opis |
|---|---|
| /h | Wymusza wykonanie testu w trybie wysokiej wydajności. |
| /i | Wykonuje testy interaktywne, które mogą być użyteczne w diagnostyce. |
| /xml ścieżka | Eksportuje wyniki testu do pliku XML w podanej ścieżce. |
| /n | Nie wykonuje zapisu wyników do bazy danych systemu. |
winsat mem /h /xml C:\wyniki_testu.xml
W powyższym przykładzie komenda winsat mem jest uruchamiana w trybie wysokiej wydajności, a wyniki testu są zapisywane w pliku XML o nazwie wyniki_testu.xml, który zostanie utworzony w katalogu C:\. Dzięki temu użytkownik może później przeanalizować wyniki testu, co może być pomocne w identyfikacji problemów z pamięcią.
Komenda winsat mfmedia w systemie Windows służy do oceny wydajności multimediów na komputerze. Umożliwia przeprowadzenie testów, które pomagają zrozumieć, jak dobrze system radzi sobie z zadaniami związanymi z odtwarzaniem multimediów, takimi jak wideo i dźwięk. Użytkownicy mogą wykorzystać tę komendę do analizy mocnych i słabych stron swojego sprzętu w kontekście multimediów.
winsat mfmedia [parametry]
| Parametr | Opis |
|---|---|
| /start | Rozpoczyna test wydajności multimediów. |
| /report | Generuje raport z wynikami testu. |
| /h | Wyświetla pomoc dotyczącą użycia komendy. |
| /c | Pozwala na uruchomienie testu w trybie cichym (bez wyświetlania dodatkowych informacji). |
winsat mfmedia /start
Wykonanie powyższej komendy rozpocznie test wydajności multimediów na komputerze. System przeanalizuje różne aspekty związane z odtwarzaniem dźwięku i wideo, a wyniki zostaną zarejestrowane w systemie. Po zakończeniu testu, użytkownik może sprawdzić wyniki, aby ocenić, jak jego sprzęt radzi sobie z multimediami.
winsat mfmedia /report
Ta komenda generuje raport z wynikami wcześniejszego testu. Użytkownik może zobaczyć szczegółowe dane dotyczące wydajności swojego sprzętu w kontekście multimediów, co może być pomocne przy podejmowaniu decyzji o ewentualnych aktualizacjach lub modernizacjach sprzętu.
WMIC (Windows Management Instrumentation Command-line) to potężne narzędzie w systemach Windows, które umożliwia interakcję z WMI (Windows Management Instrumentation) za pomocą linii poleceń. Dzięki WMIC użytkownicy mogą uzyskiwać informacje o systemie, zarządzać zasobami oraz wykonywać różnorodne operacje administracyjne w prosty i zautomatyzowany sposób.
wmic [typ] [komenda] [parametry]
| Parametr | Opis |
|---|---|
| process | Umożliwia zarządzanie procesami systemowymi. Można używać do ich przeglądania, kończenia, a także tworzenia nowych. |
| os | Pozwala na uzyskanie informacji o systemie operacyjnym, takich jak wersja, nazwa i architektura. |
| computer | Umożliwia uzyskiwanie informacji o komputerze, w tym nazwę, model oraz producenta. |
| user | Umożliwia zarządzanie kontami użytkowników i uzyskiwanie informacji o nich. |
| service | Umożliwia zarządzanie usługami systemowymi, w tym ich uruchamianiem i zatrzymywaniem. |
wmic process list
Ten przykład wyświetla listę wszystkich uruchomionych procesów na komputerze. Dzięki temu użytkownik może szybko zobaczyć, jakie aplikacje są aktywne oraz ich stan. Wyjście zawiera informacje takie jak identyfikator procesu (PID), nazwę procesu oraz jego status.
wmic os get caption, version, osarchitecture
Przykład ten umożliwia uzyskanie podstawowych informacji o systemie operacyjnym, takich jak pełna nazwa (caption), wersja oraz architektura (32-bitowa lub 64-bitowa). Jest to przydatne w sytuacjach, gdy potrzebujemy zweryfikować specyfikację systemu przed instalacją oprogramowania.
wmic user get name, sid
Komenda ta zwraca listę wszystkich użytkowników na danym systemie wraz z ich SID (Security Identifier). Informacje te mogą być użyteczne w kontekście zarządzania uprawnieniami i bezpieczeństwem systemu.
wmic service where "name='wuauserv'" call startservice
Ten przykład ilustruje, jak można uruchomić usługę Windows Update (wuauserv) za pomocą WMIC. Dzięki temu administratorzy mogą w prosty sposób zarządzać usługami systemowymi z poziomu wiersza poleceń.
Writer to polecenie w systemie Windows, które pozwala na otwieranie i edytowanie dokumentów tekstowych w programie Microsoft Word. Umożliwia szybkie uruchomienie aplikacji oraz otwarcie konkretnych dokumentów bezpośrednio z wiersza poleceń.
writer [ścieżka_do_pliku] [opcje]
| Parametr | Opis |
|---|---|
| ścieżka_do_pliku | Ścieżka do dokumentu, który ma zostać otwarty. Może być to pełna ścieżka lub nazwa pliku, jeśli znajduje się w aktualnym katalogu roboczym. |
| /m | Uruchamia program w trybie minimalnym, bez otwierania okna aplikacji. |
| /t | Tworzy nowy dokument na podstawie określonego szablonu. |
| /n | Uruchamia nową instancję programu Microsoft Word. |
writer "C:\Dokumenty\MojeDzieło.docx"
Ten przykład otwiera dokument „MojeDzieło.docx” znajdujący się w folderze Dokumenty. Użytkownik może następnie edytować zawartość dokumentu w programie Microsoft Word.
writer /n
W tym przypadku polecenie uruchamia nową instancję programu Microsoft Word, co jest przydatne, gdy użytkownik chce pracować nad wieloma dokumentami jednocześnie.
writer /t "C:\Szablony\MójSzablon.dotx"
Tutaj otwierany jest nowy dokument na podstawie szablonu „MójSzablon.dotx”. Umożliwia to szybkie tworzenie dokumentów zgodnych z określonym formatem i stylem.
Wscript to interpreter skryptów obsługiwany przez system operacyjny Windows, który umożliwia wykonywanie skryptów napisanych w językach VBScript i JScript. Dzięki Wscript użytkownicy mogą automatyzować różne zadania w systemie, takie jak zarządzanie plikami, modyfikowanie rejestru czy interakcja z aplikacjami. Wscript jest częścią Windows Script Host (WSH), co pozwala na wykonywanie skryptów bezpośrednio z poziomu systemu operacyjnego.
wscript [opcje]
| Parametr | Opis |
|---|---|
| /h:cs | Uruchamia skrypt w trybie okienkowym (z interfejsem graficznym). |
| /h:console | Uruchamia skrypt w trybie konsoli (bez interfejsu graficznego). |
| /s | Uruchamia skrypt w trybie cichym, bez komunikatów wyjściowych. |
| /nologo | Wyłącza wyświetlanie logo Wscript przy uruchamianiu skryptu. |
| plik_skryptu | Ścieżka do pliku skryptu, który ma zostać wykonany. |
wscript C:\Scripts\example.vbs
W powyższym przykładzie skrypt o nazwie example.vbs znajdujący się w katalogu C:\Scripts jest uruchamiany przy pomocy Wscript. Skrypt ten może zawierać różne instrukcje, które będą wykonywane w zależności od jego zawartości, na przykład otwieranie okien dialogowych, modyfikowanie plików czy wysyłanie e-maili.
wscript /h:cs C:\Scripts\example.vbs
W tym przykładzie skrypt example.vbs jest uruchamiany w trybie graficznym. Oznacza to, że wszelkie interaktywne elementy, takie jak okna dialogowe, będą wyświetlane użytkownikowi, co może być przydatne w przypadku skryptów wymagających inputu lub potwierdzenia od użytkownika.
wscript /s C:\Scripts\example.vbs
Ten przykład uruchamia skrypt w trybie cichym, co oznacza, że wszelkie komunikaty wyjściowe nie będą wyświetlane. Jest to szczególnie przydatne w przypadku skryptów uruchamianych automatycznie, gdy nie ma potrzeby interakcji z użytkownikiem.