KREATYWNI
Więcej o nas ... Z NATURY
NASZA OFERTA
co robimy ?
Od momentu założenia w 2004 roku, rozwija się bardzo dynamicznie. Dzięki ciągłemu rozszerzaniu świadczonych przez nas usług, stale powiększamy grupę zadowolonych klientów. To co przekonało naszych klientów to nasza elastyczność i uwzględnianie ich indywidualnych potrzeb.



PORTFOLIO
Nasze prace
Wybierz schemat → wypełnij → kod generuje się na żywo
Obsługiwane: FAQPage, Article, Product, LocalBusiness, Organization, BreadcrumbList
Dodaj pytania i odpowiedzi. Tylko wypełnione pary pojawią się w JSON-LD.
Dodaj kolejne poziomy okruszków. Kolejność = pozycja w strukturze.
Wypełnij pola po lewej → kod pojawi się tutaj jako <script type="application/ld+json">…</script>
Schemat danych (Schema lub najcześciej schema.org) – standard opisu treści na stronie w formie ustrukturyzowanych danych (structured data), który pomaga wyszukiwarkom lepiej zrozumieć, co znajduje się na stronie.
Google pokazuje rich snippets praktycznie wszędzie:
Bez JSON-LD Twoja strona wygląda jak z 2015 roku. Z JSON-LD – jak profesjonalny gracz.
FAQPage – absolutny król dodajesz pytania i odpowiedzi. Tylko wypełnione pary trafiają do kodu. Google może wyświetlić nawet 8–10 pytań naraz – to najłatwiejszy sposób na zajęcie całego pierwszego ekranu.
Article / NewsArticle / BlogPosting
Product – must-have dla sklepów
LocalBusiness – złoto dla firm lokalnych Google pokazuje: telefon, godziny otwarcia, mapę, opinie. Dodaj latitude/longitude (z Google Maps) → dokładna pinezka na mapie.
Organization Logo + sameAs (Facebook, Instagram, LinkedIn, YouTube) → Google wie, że to Ty i pokazuje ładny panel wiedzy.
BreadcrumbList Zamienia brzydki URL na ładne okruszki: Strona główna > Kategoria > Artykuł
| Typ strony / treści | Najlepszy schema JSON-LD | Co daje w Google |
|---|---|---|
| Poradniki, blogi, artykuły z pytaniami | FAQPage | Odpowiedzi wyświetlane bezpośrednio w wynikach wyszukiwania (zajmują pół ekranu!) |
| Artykuły, newsy, wpisy blogowe | Article / NewsArticle / BlogPosting | Duże zdjęcie, autor, data, wydawca – wyróżnienie w Google Discover i Top Stories |
| Produkty w sklepie internetowym | Product | Cena, dostępność, gwiazdki recenzji – rich snippets w zwykłych wynikach i Google Shopping |
| Firma lokalna (sklep, gabinet, warsztat) | LocalBusiness | Mapa, telefon, godziny otwarcia, opinie – panel lokalny po prawej i w mapach Google |
| Cała strona / firma | Organization | Logo + social media w panelu wiedzy Google (Knowledge Graph) |
| Wszystkie strony | BreadcrumbList | Ładne okruszki zamiast brzydkiego URL-a w wynikach wyszukiwania |
Generator działa 100% w przeglądarce – nic nie wysyłamy na serwer, zero logów, zero reklam.
Wklejasz gotowy kod w <head> lub przed </body> i patrzysz, jak Google zaczyna Cię lubić
Najpotężniejszy darmowy kreator robots.txt – wszystko na żywo
Włącz opcje po lewej → kod generuje się automatycznie
– wszystko, co musisz wiedzieć przed kliknięciem „Pobierz”
Wklejasz pełne adresy do sitemap.xml (np. sitemap-index.xml, sitemap-images.xml). To najważniejsza linijka w całym pliku – bez niej Google, Yandex i Bing mogą przegapić nawet 30% Twoich podstron.
Tylko dla Yandexa. Wskazujesz preferowaną wersję domeny (np. twojastrona.pl). Działa jak globalny canonical.
Googlebot, Bingbot, YandexBot, DuckDuckBot, Baiduspider – zawsze Allow: / Opcjonalnie własny crawl-delay (Yandex i Baidu potrafią zalać serwer – 2 i 5 sekund to złoty standard 2025).
Yandex i Baidu ignorują globalny crawl-delay – trzeba ustawić osobno. 2 sekundy dla Yandexa i 5 dla Baidu = spokój na serwerze.
Usuwa śmieci z URL-i (fbclid, gclid, utm_*, ref, sessionid itp.). Czyste logi, mniej duplikatów w Google Search Console.
Przykład:
/wp-admin/
/admin/
/private/
/cgi-bin/
*.pdf$
*?replytocom=
/tag/*/?sortby=
Obsługa wildcardów * i $ (koniec ścieżki) – dokładnie tak, jak lubią Google i Yandex.
| Typ strony | Co obowiązkowo włączyć |
|---|---|
| 99% zwykłych stron i sklepów | Sitemap + blokada katalogów admin (/wp-admin/, /admin/ itp.) + Clean-param (fbclid, gclid, utm_* itp.) + blokada GPTBot / ClaudeBot / CCBot |
| Blogi i sklepy z własnymi grafikami | Wszystko z góry + blokada botów obrazków (Googlebot-Image, Bingbot-Image itp. – żeby AI nie kradło zdjęć) |
| Strony, które NIE chcą być w żadnym AI | Wszystkie blokady AI: • GPTBot + ChatGPT-User • ClaudeBot + anthropic-ai • PerplexityBot • Applebot-Extended • CCBot + Bytespider + Amazonbot + blokada obrazków (opcjonalnie) |
robots.txt to tylko „grzeczna prośba”. Złe boty i tak wejdą. Do prawdziwej, twardej blokady po IP, klasach sieci i User-Agent używaj generatora .htaccess na Pro-Link.pl.
Generator działa 100% w Twojej przeglądarce – nic nie wysyłamy na serwer, zero logów, zero reklam.
Zmieniasz opcje → podgląd aktualizuje się natychmiast. Presety dla WP / PrestaShop / Laravel w 1 klik.
/kontakt. W regex możesz używać (.*) itp.$1 (Nginx/Apache rewrite).Włącz potrzebne opcje po lewej → kod pojawi się tutaj automatycznie
Krótka i konkretna legenda – żebyś wiedział dokładnie, co włączasz i dlaczego warto.
Przykład: https://example.com lub example.com
Potrzebna tylko do dwóch rzeczy: poprawnego HSTS preload i precyzyjnej blokady hotlinkingu obrazków. Jeśli nie wpiszesz – te funkcje i tak zadziałają (zostanie wstawiony uniwersalny zapis).
Wybierz, która wersja ma być kanoniczna. Google traktuje www.example.com i example.com jako dwie różne strony – trzeba wybrać jedną i przekierować drugą 301.
Po jednym w linii:/stary-adres /nowy-adres → przekierowanie wewnętrzne/stary-adres https://nowa-strona.pl → przekierowanie zewnętrzne
.htaccess to specjalny plik konfiguracyjny na serwerach WWW (głównie Apache), który pozwala zmieniać ustawienia serwera dla konkretnego katalogu bez edytowania głównej konfiguracji serwera.
Podsumowanie:
W 2025 roku dobrze skonfigurowany .htaccess to nie fanaberia – to podstawa bezpieczeństwa, szybkości i SEO. Włączasz 3-4 najważniejsze opcje i masz stronę zabezpieczoną lepiej niż 95% polskiego internetu – w 30 sekund i za darmo.
Generator jest w 100% po stronie przeglądarki – nic nie wysyłamy na serwer, zero logów, zero reklam.
Wgraj obrazek (min. 512×512 px zalecane), a my wygenerujemy wszystkie potrzebne rozmiary + gotowy kod HTML.
📁 Przeciągnij obrazek tutaj lub kliknij, żeby wybrać
Favicon pełni kilka bardzo ważnych funkcji – i tak, Google naprawdę na to patrzy!
Podsumowując: favicon to nie fanaberia – to podstawowy element brandingu i UX, który kosztuje dokładnie 5 minut pracy, a daje efekt przez lata.

Wygeneruj swoje favicony przy pomocy generatora favicon za darmo w 30 sekund ↑ i zobacz różnicę od razu!
wp-login.php i wp-admin za pomocą hasła .htaccessJednym z najczęstszych źródeł obciążenia serwerów z WordPressem są automatyczne próby logowania do panelu administracyjnego. Boty wysyłają tysiące żądań typu POST /wp-login.php, co nie tylko spowalnia stronę, ale także zajmuje zasoby PHP i CPU. Najprostszym i zarazem najskuteczniejszym sposobem, by temu zapobiec, jest zabezpieczenie plików wp-login.php oraz katalogu wp-admin hasłem HTTP (Basic Auth) w pliku .htaccess.
wp-login.phpMechanizm Basic Auth działa jeszcze przed uruchomieniem PHP. Gdy ktoś próbuje wejść na stronę wp-login.php lub wp-admin, serwer Apache sprawdza, czy użytkownik przesłał poprawny nagłówek Authorization. Jeśli nie, odsyła odpowiedź 401 Unauthorized, a przeglądarka wyświetla okienko logowania.
Dzięki temu WordPress nie wykonuje żadnego kodu, a sam serwer odcina dostęp do plików jeszcze przed uruchomieniem interpretera PHP.
.htpasswdPlik .htpasswd powinien znajdować się poza katalogiem publicznym, np.:
/home/[USER]/.htpasswds/.htpasswd
Można go wygenerować poleceniem:
htpasswd -c /home/[USER]/.htpasswds/.htpasswd admin
lub online — za pomocą generatora https://pro-link.pl/md5
.htaccessW katalogu głównym WordPressa (public_html) należy dopisać na początku pliku .htaccess poniższy fragment:
<Files "wp-login.php">
AuthType Basic
AuthName "Protected Area"
AuthUserFile /home/[USER]/.htpasswds/.htpasswd
Require valid-user
</Files>
Ta reguła sprawia, że każde wejście na adres /wp-login.php będzie wymagało wcześniejszego podania loginu i hasła z pliku .htpasswd.
wp-adminW katalogu /wp-admin należy utworzyć lub uzupełnić plik .htaccess o wpis:
<FilesMatch "admin-ajax\.php|async-upload\.php">
Satisfy any
Allow from all
</FilesMatch>
AuthType Basic
AuthName "Protected Area"
AuthUserFile /home/[USER]/.htpasswds/.htpasswd
Require user username
Dzięki temu cały panel administracyjny (/wp-admin) również będzie wymagał logowania przez to samo hasło. Reguła FilesMatch pozwala przy tym zachować dostęp do plików AJAX potrzebnych WordPressowi do działania strony.
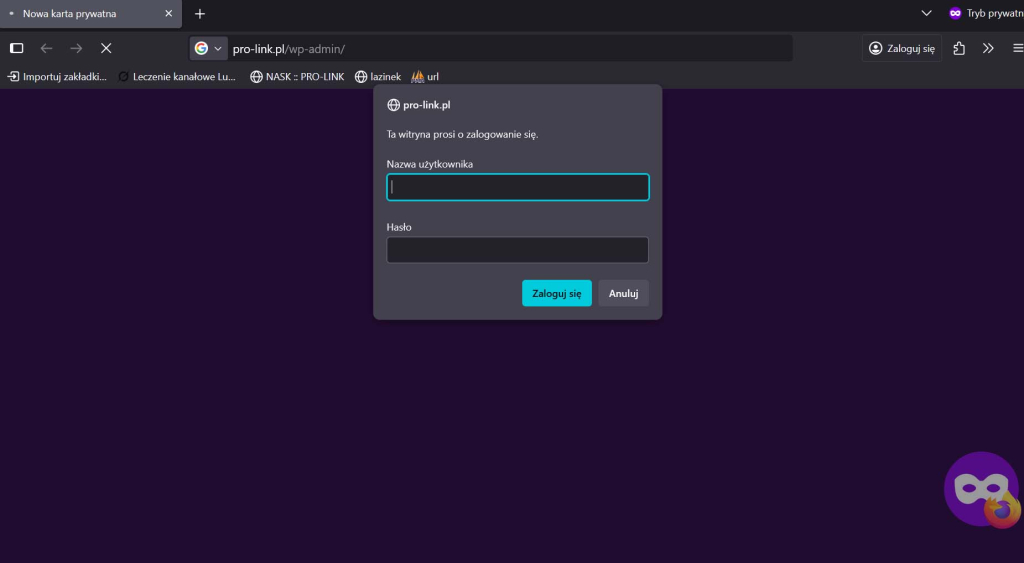
Po zapisaniu plików spróbuj wejść na adres:
https://[DOMAIN]/wp-login.php
Jeśli pojawi się okienko logowania przeglądarki (a nie formularz WordPressa), wszystko działa prawidłowo.
Można też sprawdzić z wiersza poleceń:
curl -I https://[DOMAIN]/wp-login.php
Odpowiedź powinna zawierać:
HTTP/1.1 401 Unauthorized WWW-Authenticate: Basic realm="Protected Area"
Poniżej przykład realnego ataku brute-force widocznego w logach Apache:
157.230.45.41 - - [06/Nov/2025:08:54:54 +0100] "POST //wp-login.php HTTP/1.1" 200 11063 "https://<span class="mask">[DOMAIN]</span>//wp-login.php" "Mozilla/5.0 ..."
157.230.45.41 - - [06/Nov/2025:08:54:57 +0100] "POST //wp-login.php HTTP/1.1" 200 11063 "https://<span class="mask">[DOMAIN]</span>//wp-login.php" "Mozilla/5.0 ..."
83.3.53.218 - - [06/Nov/2025:09:07:05 +0100] "GET /wp-admin HTTP/2.0" 401 490 "-" "Mozilla/5.0 ..."
83.3.53.218 - - [06/Nov/2025:09:07:28 +0100] "GET //wp-login.php HTTP/2.0" 200 3531 "-" "Mozilla/5.0 ..."
Widać tu typowy schemat: bot wysyła kolejne zapytania do wp-login.php, ale katalog wp-admin od razu odpowiada kodem 401 — dzięki poprawnie ustawionej autoryzacji Basic Auth.
wp-login.php, jak i wp-admin..htpasswd dla obu lokalizacji..htpasswd poza katalog public_html — jest to bezpieczniejsze..htaccess.Zastosowanie prostego zabezpieczenia na poziomie serwera eliminuje 99% ataków typu brute-force i znacząco zmniejsza zużycie zasobów na hostingu. To jedna z najskuteczniejszych i najprostszych metod ochrony WordPressa.
W dobie rosnącej konkurencji na rynku e-commerce, integracja różnych systemów i narzędzi staje się kluczowym elementem działalności każdego sklepu internetowego. PrestaShop, jako jedna z wiodących platform e-commerce, oferuje potężne możliwości integracji dzięki swojemu webservice API. W tym artykule przybliżymy Ci, jak korzystać z API w PrestaShop, aby zautomatyzować procesy i zwiększyć efektywność swojego sklepu.
Webservice API w PrestaShop to interfejs, który umożliwia komunikację między różnymi aplikacjami i systemami. Dzięki niemu, właściciele sklepów mogą zdalnie zarządzać swoimi danymi, takimi jak produkty, zamówienia czy klienci, bez konieczności logowania się do panelu administracyjnego. Tego typu integracje pozwalają na:
Konfiguracja Webservice API w PrestaShop jest stosunkowo prosta. Wymaga jednak kilku kroków, które należy wykonać, aby móc korzystać z pełni jego możliwości:
Webservice API to narzędzie, które można wykorzystać na wiele sposobów. Poniżej przedstawiamy kilka najpopularniejszych zastosowań:
Wykorzystanie Webservice API w sklepie PrestaShop przynosi szereg korzyści, w tym:
Webservice API w PrestaShop to niezwykle potężne narzędzie, które pozwala na integrację z różnorodnymi systemami i automatyzację wielu procesów. Dzięki temu, właściciele sklepów mogą skupić się na rozwoju swojego biznesu, zamiast na rutynowych czynnościach. Jeśli chcesz dowiedzieć się więcej o tym, jak tworzenie sklepów PrestaShop może wpłynąć na rozwój Twojego e-commerce, zachęcamy do dalszego zgłębiania tematu.
Sprawdź, jak PRO-LINK może pomóc Ci rozwinąć Twój sklep internetowy.
W dzisiejszym świecie e-commerce, dane odgrywają kluczową rolę w podejmowaniu decyzji biznesowych. W przypadku platformy PrestaShop posiadanie umiejętności zarządzania danymi jest niezwykle istotne. W tym artykule przyjrzymy się, jak wykorzystać Menedżera SQL w celu generowania raportów i wykonywania zapytań, co może znacząco wpłynąć na efektywność Twojego sklepu internetowego.
Menedżer SQL to narzędzie, które pozwala na bezpośrednią interakcję z bazą danych Twojego sklepu PrestaShop. Dzięki temu możesz nie tylko przeglądać dane, ale także tworzyć skomplikowane zapytania, które pozwalają na wyciąganie istotnych informacji z bazy. Narzędzie to jest niezwykle pomocne dla właścicieli sklepów, którzy chcą mieć pełną kontrolę nad swoimi danymi.
Tworzenie zapytań w Menedżerze SQL nie jest tak skomplikowane, jak mogłoby się wydawać. Wystarczy znać podstawy języka SQL, aby móc wyciągać interesujące nas informacje. Oto kilka podstawowych kroków do tworzenia własnych zapytań:
ps_orders zawiera informacje o zamówieniach.WHERE do określenia warunków.SELECT, aby określić, które kolumny chcesz zobaczyć w wynikach.GROUP BY i ORDER BY, aby lepiej zorganizować dane.Oto przykład zapytania, które zwraca wszystkie zamówienia złożone w ostatnich 30 dniach:
SELECT * FROM ps_orders WHERE date_add > NOW() - INTERVAL 30 DAY;Raporty są kluczowym elementem analizy danych w sklepach internetowych. Dzięki Menedżerowi SQL możesz tworzyć różnorodne raporty, które pomogą Ci zrozumieć zachowania klientów i efektywność sprzedaży. Oto kilka wskazówek, jak tworzyć raporty:
Menedżer SQL w PrestaShop to potężne narzędzie, które może znacząco poprawić zarządzanie danymi w Twoim sklepie. Dzięki elastyczności, szybkości i możliwościom analizy, możesz efektywnie monitorować wyniki swojego biznesu i podejmować informowane decyzje. Niezależnie od tego, czy jesteś właścicielem małego sklepu internetowego, czy dużego projektu e-commerce, umiejętność korzystania z Menedżera SQL jest nieoceniona.
Jeśli interesuje Cię projektowanie sklepów internetowych i chcesz dowiedzieć się więcej o możliwościach, jakie oferuje PrestaShop, odwiedź naszą stronę.
Sprawdź, jak PRO-LINK może pomóc Ci rozwinąć Twój sklep internetowy.
W dzisiejszych czasach, kiedy e-commerce rozwija się w zawrotnym tempie, zarządzanie bazą danych w systemach takich jak PrestaShop stało się kluczowym elementem sukcesu każdego sklepu internetowego. Właściwe zarządzanie bazą danych nie tylko wpływa na wydajność sklepu, ale również na bezpieczeństwo przechowywanych danych. W artykule tym omówimy znaczenie kopii zapasowych, metody ich tworzenia oraz proces przywracania danych.
Wszystkie sklepy internetowe, w tym te działające na platformie sklepy internetowe, są narażone na utratę danych z różnych powodów, takich jak błędy ludzkie, awarie sprzętu, złośliwe oprogramowanie czy ataki hakerskie. Dlatego regularne tworzenie kopii zapasowych bazy danych jest niezbędne. Oto kilka kluczowych powodów, dla których warto zadbać o kopie zapasowe:
W sklepach PrestaShop istnieje kilka sposobów na stworzenie kopii zapasowej bazy danych. Poniżej przedstawiamy najpopularniejsze metody:
PrestaShop oferuje możliwość tworzenia kopii zapasowych bezpośrednio w panelu administracyjnym. Aby to zrobić, można skorzystać z modułów dostępnych w sklepie PrestaShop lub z funkcji „Eksportuj” w zakładce bazy danych.
Można również skorzystać z narzędzi takich jak phpMyAdmin. Oto kroki, które należy wykonać:
Warto rozważyć automatyczne tworzenie kopii zapasowych. Istnieją narzędzia i skrypty, które mogą być zaprogramowane do regularnego wykonywania kopii zapasowych, co zminimalizuje ryzyko utraty danych.
W sytuacji, gdy dojdzie do utraty danych, kluczowe jest, aby wiedzieć, jak przywrócić bazę danych. Proces ten zazwyczaj obejmuje kilka kroków:
Warto zawsze upewnić się, że przywracana kopia zapasowa jest aktualna i kompletna, aby uniknąć dalszych problemów z danymi.
Bez względu na to, jak dobrze zabezpieczony jest Twój sklep PrestaShop, regularne tworzenie kopii zapasowych bazy danych powinno być priorytetem dla każdego właściciela. Dzięki odpowiednim metodom tworzenia i przywracania kopii, możesz chronić swoje dane oraz minimalizować ryzyko utraty ważnych informacji. Pamiętaj, że w dobie rosnącej konkurencji na rynku e-commerce, posiadanie solidnego zaplecza technicznego to klucz do sukcesu.
Sprawdź, jak PRO-LINK może pomóc Ci rozwinąć Twój sklep internetowy.
W świecie e-commerce, zarządzanie danymi to kluczowy element sukcesu. Właściwe zorganizowanie, importowanie i aktualizowanie informacji o produktach oraz klientach w sklepie internetowym mogą znacząco wpłynąć na efektywność sprzedaży. W tym artykule przyjrzymy się, jak efektywnie przeprowadzić import danych do sklepu PrestaShop, aby ułatwić sobie zarządzanie asortymentem oraz bazą klientów.
Import danych to proces, który umożliwia przesyłanie informacji z zewnętrznych źródeł do systemu sklepu internetowego. Jest to szczególnie przydatne w następujących sytuacjach:
PrestaShop oferuje kilka metod importowania danych. Poniżej przedstawiamy najczęściej stosowane podejścia:
Najpopularniejszą metodą importu danych w PrestaShop jest użycie plików CSV. W tym celu należy:
Dla bardziej zaawansowanych użytkowników, PrestaShop oferuje różne moduły, które mogą ułatwić import danych. Moduły te często oferują dodatkowe funkcje, takie jak:
Warto rozważyć zainwestowanie w odpowiedni moduł, szczególnie jeśli planujesz regularne aktualizacje danych w swoim sklepie PrestaShop.
Podczas importu danych mogą wystąpić różne problemy. Oto kilka z nich oraz sposoby ich rozwiązania:
Import danych do sklepu internetowego PrestaShop to kluczowy proces, który może znacząco wpłynąć na zarządzanie asortymentem oraz relacjami z klientami. Dzięki odpowiednim narzędziom i technikom, można zautomatyzować wiele czynności, oszczędzając czas i redukując ryzyko błędów.
Pamiętaj, że zarówno projektowanie sklepów internetowych, jak i ich późniejsze zarządzanie, wymaga ciągłej pracy nad optymalizacją procesów. Dlatego warto zainwestować w narzędzia oraz szkolenia, które umożliwią Ci sprawne zarządzanie danymi.
Sprawdź, jak PRO-LINK może pomóc Ci rozwinąć Twój sklep internetowy.
W każdym nowoczesnym sklepie internetowym, takim jak PrestaShop, kluczowym elementem zarządzania jest odpowiednie monitorowanie zdarzeń, które odbywają się w systemie. Dziennik zdarzeń, często nazywany logami, jest narzędziem, które pozwala na śledzenie i analizowanie działań w sklepie. Dzięki temu przedsiębiorcy mogą nie tylko zidentyfikować potencjalne problemy, ale również optymalizować działanie swojego biznesu.
Dziennik zdarzeń to zbiór informacji rejestrujących działania użytkowników oraz systemu w danym okresie. W przypadku sklepów internetowych, logi mogą obejmować szereg zdarzeń, takich jak:
Monitorowanie logów w sklepie internetowym przynosi wiele korzyści:
Aby maksymalizować korzyści z monitorowania logów, warto wdrożyć kilka praktycznych wskazówek:
Monitorowanie dziennika zdarzeń w sklepie internetowym opartym na PrestaShop jest kluczowym elementem zapewniającym bezpieczeństwo i efektywność działania. Regularne przeglądanie logów oraz analiza zebranych danych umożliwiają szybką reakcję na pojawiające się problemy i optymalizację procesów. Dzięki temu przedsiębiorcy mogą skupić się na rozwoju swojego biznesu, a nie na usuwaniu usterek.
Jeśli chcesz dowiedzieć się więcej o tym, jak efektywnie projektować i zarządzać sklepami internetowymi, zachęcamy do odwiedzenia naszej strony. Sprawdź, jak PRO-LINK może pomóc Ci rozwinąć Twój sklep internetowy.