Od momentu założenia w 2004 roku, rozwija się bardzo dynamicznie. Dzięki ciągłemu rozszerzaniu świadczonych przez nas usług, stale powiększamy grupę zadowolonych klientów. To co przekonało naszych klientów to nasza elastyczność i uwzględnianie ich indywidualnych potrzeb.
Strony internetowe optymalizacja seo
Strona WWW jest głównym źródłem informacji i interaktywnym środowiskiem kontaktu z klientem.
Strona WWW jest głównym źródłem informacji i interaktywnym środowiskiem kontaktu z klientem. Jest to równocześnie najtańszy sposób zareklamowania się szerokiemu gronu klientów i kontrahentów. Jakie funkcje powinna spełniać Twoja strona internetowa?
PORTFOLIO
Nasze prace
Symulator Google SERP według miasta – symulacja wyników lokalnych
Narzędzie Symulator Google SERP dla miasta pozwala sprawdzić, jak mogą wyglądać wyniki wyszukiwania Google dla konkretnej lokalizacji geograficznej – bez konieczności zmiany IP, używania VPN czy trybu incognito. To praktyczne rozwiązanie stworzone z myślą o specjalistach SEO, marketerach oraz właścicielach firm działających lokalnie.
Dzięki wykorzystaniu parametru uule (geo-lokalizacja) oraz wyłączeniu personalizacji wyników (pws=0), narzędzie generuje możliwie najczystszy i najbardziej obiektywny SERP, zbliżony do tego, jaki widzi użytkownik wyszukujący frazę w danym mieście.
Co możesz sprawdzić?
widoczność strony w Local SEO dla wybranego miasta
różnice w wynikach Google pomiędzy lokalizacjami
pozycje stron lokalnych konkurentów
sposób wyświetlania wyników dla różnych języków (hl) i krajów (gl)
poprawność targetowania fraz typu „usługa + miasto”
Jak działa narzędzie?
Wpisz zapytanie (np. notariusz Katowice).
Wybierz miasto z listy (obsługiwane są miasta w Polsce i za granicą).
Ustaw kraj i język wyszukiwarki Google.
Otwórz wygenerowany link lub skopiuj go do dalszej analizy.
Dla kogo jest to narzędzie?
agencji SEO i freelancerów
firm pozycjonujących się lokalnie
osób analizujących konkurencję w Google
twórców treści i strategii pod Local Pack / Mapy Google
FAQ – wyniki Google w innych lokalizacjach
Jak sprawdzić wyniki Google w innym mieście?
Aby sprawdzić wyniki Google dla innego miasta, nie wystarczy dopisać nazwy miasta w zapytaniu. Google dopasowuje wyniki do lokalizacji użytkownika (IP/GPS), historii wyszukiwań i personalizacji. Najdokładniej zrobisz to przez symulację lokalizacji (np. parametr UULE) oraz wyłączenie personalizacji wyników (pws=0). Dzięki temu zobaczysz możliwie „czysty” SERP dla wskazanego miasta.
Jak sprawdzić pozycję strony w innej lokalizacji?
Pozycje mogą różnić się między miastami nawet przy tej samej frazie. Aby sprawdzić pozycję w innej lokalizacji: wybierz konkretne miasto, ustaw kraj (gl) i język (hl), a następnie sprawdź wyniki z wyłączoną personalizacją (pws=0). To pozwala porównywać wyniki w sposób bardziej powtarzalny.
Dlaczego widzę inne wyniki wyszukiwania niż klient?
To normalne. Google różnicuje wyniki na podstawie lokalizacji (miasto/region), historii wyszukiwań, zalogowania do konta Google, typu urządzenia (desktop/mobile) oraz testów A/B. Dlatego Ty, klient i agencja możecie widzieć inne wyniki mimo identycznej frazy.
Jak wyłączyć lokalizację w Google przy sprawdzaniu pozycji?
W praktyce nie da się całkowicie „wyłączyć” lokalizacji w standardowej wyszukiwarce. Tryb incognito czy wylogowanie nie gwarantują neutralnych wyników. Najbliżej „czystych” wyników jest: wyłączenie personalizacji (pws=0) oraz ręczne ustawienie lokalizacji (np. UULE) zamiast bieżącej lokalizacji użytkownika.
Jak sprawdzić Local Pack w innym mieście?
Local Pack (wyniki z Map/3 firmy) jest najmocniej zależny od lokalizacji. Aby sprawdzić Local Pack w innym mieście, trzeba zasymulować dokładną lokalizację geograficzną i porównać wyniki dla różnych miast osobno. VPN często nie wystarcza, bo Local Pack bywa wyliczany na podstawie wielu sygnałów, nie tylko IP.
Kilobajt (KB) – czym jest i ile to naprawdę danych?
Kilobajt to jedna z pierwszych „większych” jednostek danych, z jakimi spotyka się każdy użytkownik komputera. Pojawia się przy rozmiarach plików, zdjęć, dokumentów, e-maili czy stron WWW. Choć brzmi prosto, kilobajt bywa źródłem nieporozumień – zwłaszcza gdy w grę wchodzą różnice między KB a KiB. W tym artykule dokładnie wyjaśniamy, czym jest kilobajt, ile ma bajtów, skąd biorą się różnice w definicjach i jak poprawnie go interpretować w praktyce.
Czym jest kilobajt?
Kilobajt to jednostka informacji większa od bajta, używana do opisu niewielkich ilości danych. Symbol jednostki to KB.
Najprościej mówiąc: kilobajt to „kilka tysięcy bajtów”, ale dokładna liczba zależy od tego, jaką definicję przyjmiemy.
KB a KiB – dwie definicje kilobajta
To najważniejszy fragment całego zagadnienia. W informatyce funkcjonują dwie definicje kilobajta:
1) Kilobajt dziesiętny (SI)
Zgodnie z układem SI:
1 KB = 1000 B
Ta definicja jest powszechnie używana:
w marketingu,
w opisach nośników danych,
w sieciach komputerowych,
w dokumentacji technicznej producentów.
2) Kibibajt (binarny)
W systemach komputerowych opartych na potęgach dwójki używa się jednostki:
1 KiB = 1024 B
Skrót KiB (kibibajt) został wprowadzony po to, aby jednoznacznie odróżnić jednostki binarne od dziesiętnych.
Kilobajt a bajt – zależność
Bajt jest jednostką bazową, a kilobajt jej wielokrotnością:
1 KB = 1000 bajtów,
1 KiB = 1024 bajty.
Dla porównania:
1 bajt = 8 bitów,
1 KB ≈ 8000 bitów,
1 KiB = 8192 bity.
Ta różnica wydaje się niewielka przy jednym kilobajcie, ale rośnie wraz z większymi jednostkami (MB, GB, TB).
Ile to jest 1 KB w praktyce?
Kilobajt to niewielka ilość danych, ale wciąż bardzo użyteczna. Przykładowo:
krótki plik tekstowy (kilkaset znaków) → kilka KB,
pojedynczy e-mail bez załączników → kilka–kilkanaście KB,
prosty plik HTML strony WWW → 5–50 KB,
mała ikona lub favicon → 1–10 KB.
W czasach wolnych łączy internetowych (modemy, ISDN) optymalizacja „kilobajtów” miała ogromne znaczenie. Do dziś ma to sens w kontekście SEO, wydajności i Core Web Vitals.
Kilobajty w plikach i dokumentach
Rozmiar pliku w kilobajtach zależy od rodzaju danych:
TXT – bardzo małe pliki, zwykle kilka KB,
HTML / CSS / JS – od kilku do kilkuset KB,
PDF – od kilkudziesięciu KB do wielu MB,
obrazy – od kilku KB (ikony) do tysięcy KB (zdjęcia).
System plików nie „rozumie” zawartości – dla niego każdy plik to po prostu sekwencja bajtów, a kilobajt to tylko jednostka miary.
Kilobajt a prędkość internetu
W internecie prędkości podawane są w bitach na sekundę, natomiast pliki mierzymy w bajtach i kilobajtach. To częste źródło nieporozumień.
Przykład:
łącze 8 Mb/s → maks. ok. 1 MB/s,
strona ważąca 500 KB → pobierze się w ułamku sekundy.
Dlatego zmniejszenie strony z 500 KB do 300 KB realnie wpływa na szybkość ładowania – zwłaszcza na mobile.
Skąd wzięła się różnica 1000 vs 1024?
Komputery działają w systemie binarnym, więc naturalną jednostką była potęga dwójki:
210 = 1024
Przez lata słowo „kilobajt” było potocznie używane na określenie 1024 bajtów. Gdy jednak nośniki danych zaczęły być liczone marketingowo, wprowadzono ścisłe rozróżnienie:
KB = 1000 B (SI),
KiB = 1024 B (binarnie).
Dzięki temu dziś da się precyzyjnie określić, czy mówimy o jednostce dziesiętnej czy binarnej.
Najczęstsze błędy i nieporozumienia
traktowanie KB i KiB jako tego samego,
nieświadomość, że system operacyjny może używać KiB,
mylenie kilobajtów z kilobitami (KB vs kb),
zakładanie, że „kilobajt to zawsze 1024 bajty”.
FAQ
Ile bajtów ma kilobajt?
Zależnie od definicji: 1000 B (KB) lub 1024 B (KiB).
Czy KB i KiB to to samo?
Nie. KB to jednostka dziesiętna, KiB – binarna.
Dlaczego system pokazuje inne wartości niż producent dysku?
Producent liczy w KB/MB/GB (dziesiętnie), a system często wyświetla w KiB/MiB/GiB.
Podsumowanie
Kilobajt to podstawowa jednostka opisu niewielkich plików i danych. Kluczowe jest zrozumienie różnicy między KB (1000 B) a KiB (1024 B), bo to ona stoi za wieloma „rozbieżnościami” w systemach i nośnikach danych.
Bajt – podstawowa jednostka danych w informatyce
Bajt to jedna z najczęściej używanych jednostek w informatyce. Spotykasz go przy rozmiarach plików, pamięci RAM, dysków, baz danych czy transferów. Choć wszystko w komputerze opiera się na bitach, to właśnie bajt jest praktyczną „cegiełką”, na której operują systemy operacyjne i programy. W tym artykule dokładnie wyjaśniamy, czym jest bajt, ile ma bitów, skąd się wziął i jak go poprawnie rozumieć w praktyce.
Czym jest bajt?
Bajt (ang. byte) to standardowa jednostka danych w informatyce, składająca się z 8 bitów. Bajt jest najmniejszą porcją informacji, którą większość komputerów potrafi przetwarzać i adresować bezpośrednio.
W praktyce bajt służy do zapisu:
pojedynczego znaku tekstowego,
małej liczby całkowitej,
fragmentu obrazu lub dźwięku,
elementów struktur danych.
Bajt a bit – kluczowa różnica
Podstawowa zależność, którą warto zapamiętać:
1 bajt (B) = 8 bitów (b)
Bit może przyjmować wartość 0 albo 1. Bajt natomiast, jako zbiór 8 bitów, może reprezentować:
28 = 256 różnych wartości (od 0 do 255).
To właśnie ta liczba sprawia, że bajt jest tak wygodny — pozwala zapisać litery, cyfry, znaki specjalne lub niewielkie liczby w jednym „pakiecie”.
Dlaczego bajt ma 8 bitów?
Historycznie bajt nie zawsze miał 8 bitów — w początkach informatyki spotykano bajty 6-, 7- czy 9-bitowe. Z czasem jednak 8 bitów okazało się najlepszym kompromisem:
256 możliwych wartości wystarczało na znaki i liczby,
8 jest potęgą dwójki — idealne dla elektroniki cyfrowej,
łatwo dzielić i grupować dane w pamięci.
Wraz z popularyzacją kodu ASCII i architektur komputerów osobistych bajt 8-bitowy stał się światowym standardem.
Bajt w praktyce komputerowej
W codziennym użytkowaniu komputera niemal wszystko jest liczone w bajtach:
rozmiar plików (np. 350 KB, 2 MB, 4 GB),
pamięć RAM (np. 16 GB),
pojemność dysków (np. 1 TB),
bazy danych i logi systemowe.
Systemy operacyjne adresują pamięć właśnie bajtami, dlatego mówi się, że komputer jest „bajtowo adresowalny”.
Bajt a kodowanie znaków (ASCII, Unicode)
W klasycznym ASCII jeden znak zajmuje 1 bajt. Dzięki temu można było zapisać 128 (a później 256) znaków: litery alfabetu, cyfry i podstawowe symbole.
Współczesne systemy używają Unicode (najczęściej UTF-8), gdzie:
znaki ASCII nadal zajmują 1 bajt,
polskie znaki (ą, ć, ł…) zajmują zwykle 2 bajty,
emoji mogą zajmować 4 bajty.
To wyjaśnia, dlaczego pliki tekstowe z emoji są większe niż te same pliki zawierające tylko litery alfabetu.
Bajty w pamięci i plikach
Każdy plik to po prostu sekwencja bajtów. System plików nie „wie”, czy dany bajt jest literą, pikselem czy fragmentem programu — to aplikacja nadaje tym bajtom znaczenie.
Przykładowo:
plik tekstowy → bajty interpretowane jako znaki,
obraz → bajty jako kolory pikseli,
program → bajty jako instrukcje procesora.
Jednostki większe od bajta
Bajt jest punktem wyjścia do większych jednostek:
1 KB = 1000 B (dziesiętnie)
1 MB = 1000 KB
1 GB = 1000 MB
1 TB = 1000 GB
W systemach operacyjnych często spotyka się też wersje binarne: KiB, MiB, GiB, gdzie:
1 KiB = 1024 B
1 MiB = 1024 KiB
1 GiB = 1024 MiB
To właśnie ta różnica powoduje, że „dysk 1 TB” w systemie wygląda jak ok. 931 GiB.
Bajty a prędkość internetu
Prędkość internetu podaje się zazwyczaj w bitach na sekundę (Mb/s), a nie w bajtach. Dlatego rzeczywista prędkość pobierania plików (MB/s) jest około 8 razy mniejsza.
Przykład:
łącze 200 Mb/s → maks. ok. 25 MB/s,
łącze 600 Mb/s → maks. ok. 75 MB/s.
Najczęstsze błędy i nieporozumienia
mylenie B (bajtów) z b (bitami),
oczekiwanie, że 100 Mb/s = 100 MB/s,
traktowanie KB i KiB jako tego samego,
zakładanie, że każdy znak tekstu zajmuje 1 bajt (Unicode!).
FAQ
Ile bitów ma bajt?
Standardowo 8 bitów.
Czy bajt zawsze ma 8 bitów?
W nowoczesnej informatyce – tak. Historycznie bywało inaczej, ale dziś 8-bitowy bajt to globalny standard.
Czy 1 znak = 1 bajt?
Tylko w ASCII. W Unicode jeden znak może zajmować od 1 do 4 bajtów.
Podsumowanie
Bajt to podstawowa, praktyczna jednostka danych w informatyce. Składa się z 8 bitów i pozwala reprezentować znaki, liczby oraz fragmenty danych. Zrozumienie bajta ułatwia interpretację rozmiarów plików, pamięci, dysków oraz realnych prędkości internetu.
Bit – najmniejsza jednostka informacji w informatyce
Bit (ang. binary digit) to absolutna podstawa świata cyfrowego. Wszystko, co widzisz na ekranie — tekst, zdjęcia, muzyka, wideo, strony WWW, gry, a nawet szyfrowanie bankowe — da się ostatecznie sprowadzić do ciągów 0 i 1. W tym artykule rozkładamy „bit” na czynniki pierwsze: czym jest, jak działa, jak liczyć bity, gdzie je spotykasz oraz dlaczego w praktyce łatwo pomylić bit (b) z bajtem (B).
Czym jest bit?
Bit to najmniejsza jednostka informacji w informatyce i telekomunikacji. Może przyjąć tylko jedną z dwóch wartości: 0 albo 1. Dzięki temu idealnie pasuje do elektroniki cyfrowej, gdzie łatwo rozróżnić dwa stany — np. niski/wysoki poziom napięcia, brak/sygnał, wyłączone/włączone.
Warto zauważyć: bit to nie tylko „cyferka”. Bit to także nośnik decyzji i niepewności. Jeśli odpowiedź na pytanie brzmi „tak/nie”, to do jej zapisu wystarczy 1 bit. Jeśli mamy cztery możliwe odpowiedzi, potrzebujemy 2 bitów (bo 2 bity dają 4 kombinacje).
Trochę historii i teoria informacji
Pojęcie bitu spopularyzowała teoria informacji, kojarzona głównie z Claude’em Shannonem. Kluczowa intuicja jest prosta: informację można traktować jak coś, co da się kodować w postaci decyzji binarnych. Dlatego „0/1” stało się uniwersalnym językiem komputerów.
W praktyce to właśnie ta idea pozwoliła budować: kompresję danych (mniej bitów na to samo znaczenie), szyfrowanie (mieszanie bitów według reguł), korekcję błędów (dodatkowe bity kontrolne), transmisję (bity na sekundę).
Bit vs bajt: b a B (najczęstsze pomyłki)
To klasyczny „zgrzyt” w IT: bit zapisujemy małą literą b, a bajt wielką literą B. Różnica jest ogromna:
1 b = 1 bit
1 B = 8 bitów = 8 b
Dlatego: 100 Mb/s (megabitów na sekundę) to nie to samo co 100 MB/s (megabajtów na sekundę). W uproszczeniu:
Przykład: internet 300 Mb/s w idealnych warunkach da maksymalnie około 37,5 MB/s pobierania (300 ÷ 8). A w praktyce bywa mniej, bo dochodzą nagłówki protokołów, Wi-Fi, obciążenie sieci i serwerów.
Jak komputer „widzi” bity?
W elektronice cyfrowej bit jest realizowany fizycznie: tranzystorami, kondensatorami, komórkami pamięci, stanami magnetycznymi. W programowaniu bit jest abstrakcją, ale mocno powiązaną ze sprzętem. Procesor operuje na rejestrach (np. 64-bitowych), pamięć jest adresowana bajtami, a pliki to sekwencje bajtów.
bit depth — „głębia bitowa” w grafice i audio (np. 8/10/12/16 bitów)
System dwójkowy i przykłady zapisu
Bit jest cyfrą w systemie dwójkowym. Liczby w binarnym zapisie powstają tak jak w dziesiętnym, tylko zamiast podstawy 10 mamy podstawę 2. Każda kolejna pozycja to rosnąca potęga dwójki:
Pozycje (od prawej): 1 2 4 8 16 32 64 128
Bity: b0 b1 b2 b3 b4 b5 b6 b7
Taki ciąg 8 bitów to 1 bajt. Ten sam bajt może oznaczać: liczbę 202, jakiś znak w danym kodowaniu, albo fragment koloru/piksela — zależy od interpretacji.
Operacje bitowe: AND, OR, XOR, NOT i przesunięcia
Operacje bitowe są bardzo szybkie i występują wszędzie: od sterowników, przez kryptografię, po optymalizacje. Najważniejsze:
AND (&): 1 tylko wtedy, gdy oba bity są 1
OR (|): 1, gdy przynajmniej jeden bit jest 1
XOR (^): 1, gdy bity są różne
NOT (~): odwraca bit (0→1, 1→0)
SHIFT (<<, >>): przesunięcia w lewo/prawo
Przykład na liczbach (intuicyjnie)
Załóżmy:
a = 10101010
b = 11001100
AND:
a & b = 10001000
OR:
a | b = 11101110
XOR:
a ^ b = 01100110
Przesunięcia
Przesunięcie w lewo o 1 (<< 1) zwykle odpowiada mnożeniu przez 2 (w obrębie zakresu). Przesunięcie w prawo o 1 (>> 1) zwykle odpowiada dzieleniu przez 2.
Bitmaski to jeden z najpraktyczniejszych powodów, dla których „bit” jest tak ważny. Zamiast przechowywać wiele wartości typu „tak/nie” osobno, można upchnąć je w jeden liczbowy „pakiet” bitów. Każdy bit oznacza jedną cechę (flagę).
Przykład: uprawnienia
Załóżmy trzy uprawnienia:
odczyt (R) = 1
zapis (W) = 2
wykonanie (X) = 4
Wtedy:
R = 001
W = 010
X = 100
R+W = 011 (czyli 3)
R+X = 101 (czyli 5)
R+W+X = 111 (czyli 7)
To dokładnie ta logika stoi m.in. za uprawnieniami w systemach Unix/Linux (np. 755, 644).
Bity w sieciach: Mb/s, maski, IP i narzut protokołów
Przepływność
W sieciach prędkość zwykle podaje się w bitach na sekundę (b/s). Stąd popularne: kb/s, Mb/s, Gb/s. Producenci i operatorzy prawie zawsze używają Mb/s, bo liczby wyglądają „lepiej” niż w MB/s.
Adresy IP a bity
Adres IPv4 ma 32 bity. Maska (np. /24) mówi, ile bitów opisuje sieć, a ile hosty. Przykład 192.168.1.0/24 oznacza, że:
24 bity to część sieci
8 bitów to część hosta (czyli 28 = 256 adresów, w praktyce mniej użytecznych)
Narzut protokołów
Nawet jeśli łącze ma X Mb/s, realny transfer pliku bywa mniejszy. Dzieje się tak, bo część transmisji to dane „pomocnicze”: nagłówki Ethernet/IP/TCP/UDP, potwierdzenia, retransmisje, a w Wi-Fi dodatkowo mechanizmy kontroli medium. To normalne.
Ile bitów potrzeba do… (ASCII/Unicode, kolory, audio, wideo)
Tekst
W klasycznym ASCII jeden znak to 7 bitów (często przechowywane w 8 bitach = 1 bajt). W nowoczesnych systemach króluje Unicode (np. UTF-8), gdzie jeden znak może zająć 1–4 bajty, zależnie od tego, jaki to znak (łaciński, polski, emoji, znaki azjatyckie itp.).
Kolory w grafice
Wiele obrazów używa modelu RGB po 8 bitów na kanał:
R: 8 bitów
G: 8 bitów
B: 8 bitów
Razem daje to 24 bity na piksel (czyli 16 777 216 możliwych kolorów). Gdy dochodzi kanał alfa (przezroczystość), mamy zwykle 32 bity na piksel (RGBA).
Audio
„Głębia bitowa” w audio (np. 16-bit, 24-bit) wpływa na zakres dynamiki i poziom szumów kwantyzacji. CD audio to klasycznie 16 bitów na próbkę przy 44,1 kHz. W studiu często spotkasz 24 bity.
Wideo
Wideo to ogrom danych, dlatego tak ważna jest kompresja. W praktyce liczy się nie tylko „ile bitów”, ale: rozdzielczość, klatkaż, kodek, bitrate, profil, sceny (szczegółowość, ruch). Stąd na platformach streamingowych kluczowy parametr to często bitrate (Mb/s).
Jednostki większe niż bit: k/M/G/T i wersje binarne (KiB/MiB)
W praktyce spotkasz dwa „światy” jednostek:
1) Dziesiętne (SI) — najczęściej marketing, dyski, sieci
1 kb = 1000 b
1 Mb = 1000 kb = 1 000 000 b
1 Gb = 1 000 000 000 b
2) Binarne (IEC) — często systemy operacyjne, RAM, techniczne opisy
1 Kib = 1024 b
1 Mib = 1024 Kib
1 Gib = 1024 Mib
Analogicznie dla bajtów: KB/MB/GB (dziesiętne) vs KiB/MiB/GiB (binarne). To tłumaczy, dlaczego „dysk 1 TB” w systemie może wyglądać jak ~931 GiB. To nie „brak” pamięci, tylko różnica definicji jednostek.
Typowe błędy i szybkie porady
Mylenie b i B: Mb/s to megabity, MB/s to megabajty. Różnica ×8.
„Mam 1 Gb internetu, czemu nie pobiera 1 GB/s?” Bo 1 Gb/s ≈ 125 MB/s w idealnych warunkach, a w praktyce zwykle mniej.
„Dysk ma mniej niż na pudełku” – producent liczy dziesiętnie (TB), system często pokazuje binarnie (TiB/GiB).
Bitrate to nie rozdzielczość: 1080p może wyglądać świetnie lub słabo — zależy od bitrate’u i kodeka.
FAQ
Czy bit zawsze oznacza 0 albo 1?
W klasycznej informatyce cyfrowej tak. Są jednak dziedziny (np. informatyka kwantowa), gdzie spotyka się inne modele. W codziennych zastosowaniach IT bit to po prostu 0/1.
Ile bitów ma bajt?
8 bitów. To standard powszechny praktycznie we wszystkich współczesnych systemach.
Skąd się bierze „64-bitowy system”?
Najprościej: z architektury procesora i szerokości rejestrów/adresowania. 64 bity pozwala m.in. adresować dużo większą przestrzeń pamięci niż 32 bity.
Co oznacza „głębia bitowa” w grafice?
To liczba bitów używana do opisu koloru (lub kanału). Np. 8 bitów na kanał w RGB daje 24 bity na piksel. Większa głębia to zwykle płynniejsze przejścia tonalne (mniej bandingu), szczególnie w HDR.
Podsumowanie
Bit to fundament całej informatyki: najmniejsza porcja informacji, z której buduje się bajty, pliki, obrazy, dźwięk, wideo i transmisję w sieciach. Zrozumienie bitu szybko rozjaśnia wiele „miejskich legend”: dlaczego prędkości internetu podaje się w Mb/s, czemu dysk ma „mniej”, jak działają maski sieciowe i czemu operacje bitowe są tak ważne w systemach i bezpieczeństwie.
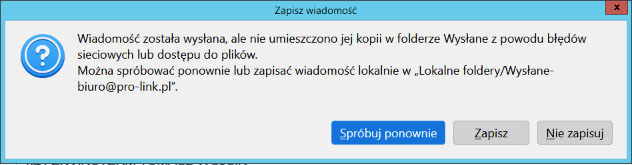
Podczas wysyłania e-maili w Mozilla Thunderbird możesz natknąć się na komunikat:
Wiadomość została wysłana, ale nie umieszczono jej kopii w folderze Wysłane z powodu błędów sieciowych lub dostępu do plików. Można spróbować ponownie lub zapisać wiadomość lokalnie w „Lokalne foldery/Wysłane-biuro@pro-link.pl”.
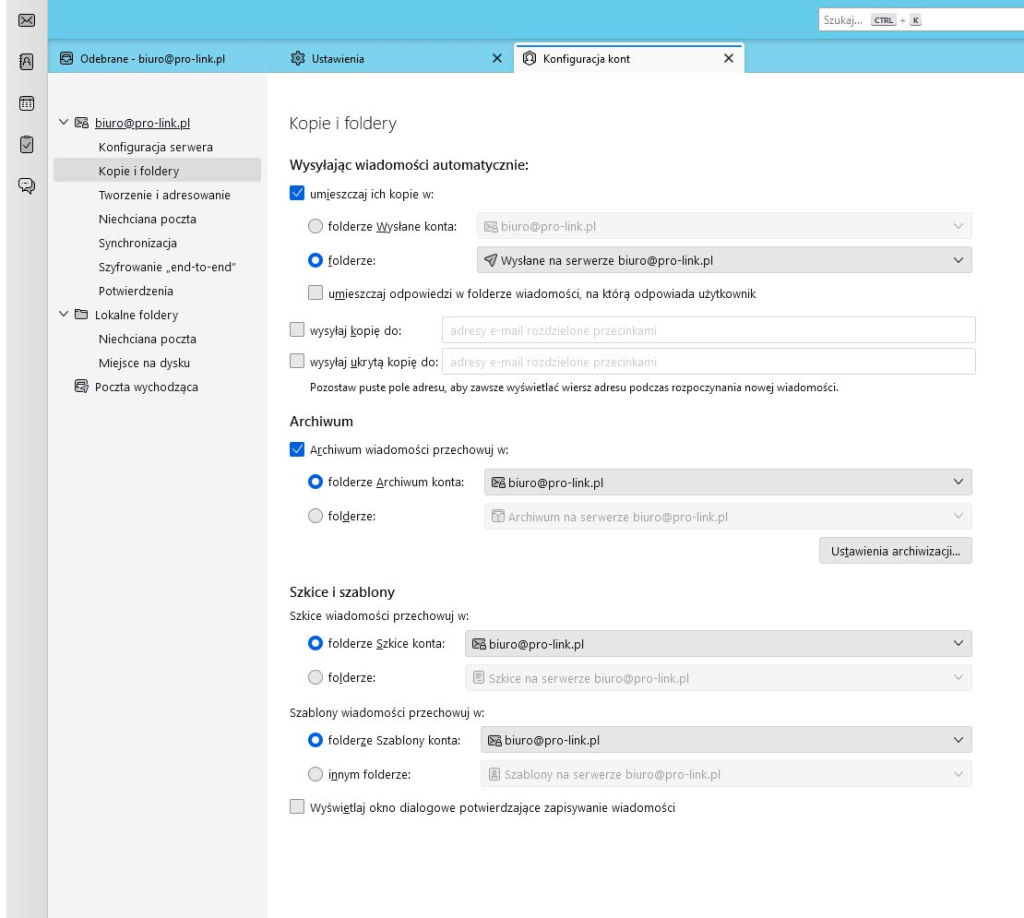
Program sugeruje wtedy zapis wiadomości lokalnie w Lokalne foldery/Wysłane [adres email]. Najczęstszą przyczyną tego problemu nie jest sama sieć, ale nieprawidłowo wskazany folder „Wysłane” na serwerze IMAP.
Poniżej pokazuję, jak poprawnie ustawić folder – dokładnie tak, jak na załączonym screenie.
wiadomości są widoczne na innych urządzeniach (telefon, webmail)
Po zapisaniu zmian
Kliknij OK
Zamknij i ponownie uruchom Thunderbird
Wyślij testową wiadomość
Jeżeli wszystko jest poprawnie ustawione:
błąd nie pojawi się ponownie
kopia maila trafi do folderu Wysłane na serwerze
wiadomość będzie widoczna także w webmailu
Podsumowanie
Komunikat o braku kopii w folderze „Wysłane” w Thunderbirdzie:
nie oznacza, że mail się nie wysłał
oznacza błędnie wskazany folder IMAP
Rozwiązanie jest proste:
Ustaw zapisywanie kopii w folderze „Wysłane” na serwerze, a nie lokalnie.
To jedna z najczęstszych i najbardziej mylących konfiguracji w Thunderbirdzie – a jednocześnie jedna z najłatwiejszych do naprawienia.
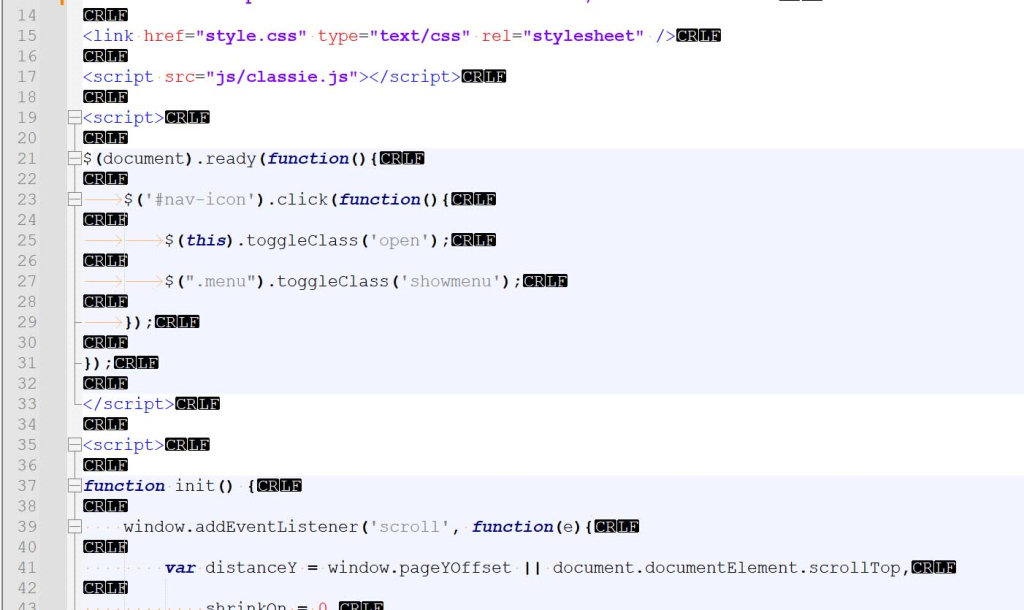
Jak naprawić podwójne puste linie w plikach po edycji w Visual Studio lub Windows
W pracy z kodem HTML, CSS czy JS często zdarza się, że plik edytowany w różnych środowiskach (np. Visual Studio, Notepad++, edytor FTP, IDE na Windows) zaczyna wyglądać dziwnie — linijki kodu są przedzielone pustymi liniami, a edytor wyświetla oznaczenia CRLF przy każdej z nich.
To problem, który dotyczy wielu webmasterów. Na szczęście jego rozwiązanie jest banalne.
W tym artykule wyjaśniam:
skąd biorą się podwójne puste linie,
jak działa CRLF / LF,
jak to naprawić w Notepad++ jednym kliknięciem,
jakie wyrażenie regularne usuwa wszystkie fałszywe puste linie z pliku.
Skąd biorą się puste linie w kodzie? Powód jest prosty: CR + CRLF
Windows używa końcówek linii CRLF, podczas gdy Linux używa LF. Visual Studio potrafi dodatkowo nadpisać plik w formie:
CR LF CR LF
czyli podwójnych końców linii. Notepad++ wyświetla wtedy kod w taki sposób:
<kod> CRLF
CRLF
<kod> CRLF
CRLF
Czyli każda linia ma „fałszywą pustą linię” pomiędzy.
Dla edytora to wygląda jak… puste linie, mimo że ich nie było w oryginale.
Jak łatwo naprawić podwójne linie w Notepad++?
1. Włącz widoczność końców linii
W menu:
Widok → Niewidoczne znaki → Pokaż końce linii
Zobaczysz oznaczenia:
CRLF – Windows
LF – Unix
Jeśli zobaczysz podwójne CRLF — problem potwierdzony.
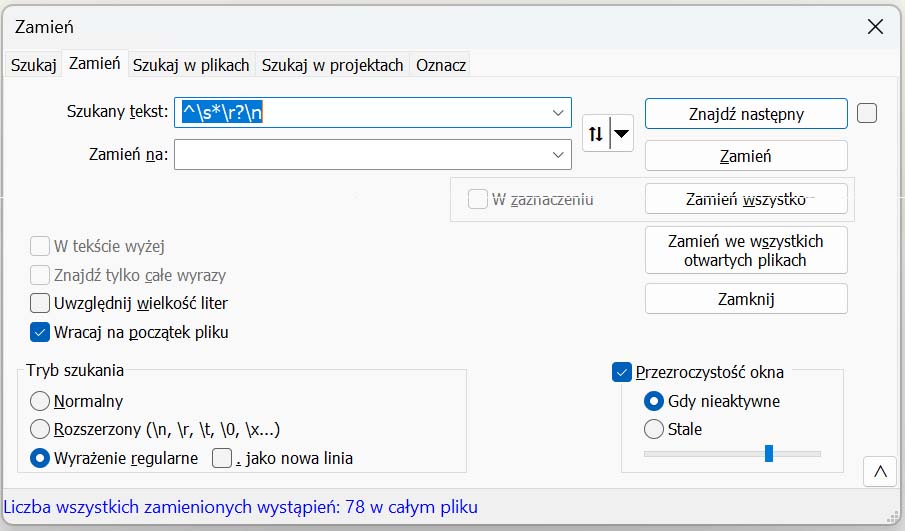
2. Usuń puste linie wyrażeniem regularnym (najlepsza metoda)
Otwórz okno „Zamień” (Ctrl + H), zaznacz:
Tryb: Wyrażenie regularne
(nie zaznaczaj „Rozszerzony”)
I użyj tego:
Szukaj:
^\s*\r?\n
Zamień na:
(puste)
Kliknij Zamień wszystko.
Efekt:
wszystkie fałszywe puste linie znikają,
kod wraca do normalnej postaci,
plik staje się czytelny i zgodny z IDE.
3. Jeśli chcesz pozostawić tylko jedną pustą linię (np. między sekcjami)
Użyj:
Szukaj:
(\r?\n){2,}
Zamień na:
\r\n
To zostawi jedną pustą linię zamiast wielu.
4. Konwersja końców linii (opcjonalnie)
Aby wymusić spójny format linii:
Format → Konwertuj na UNIX (LF) lub Format → Konwertuj na Windows (CRLF)
Po zapisaniu plik będzie jednolity.
Podsumowanie
Podwójne linie w Notepad++ nie wynikają z błędu edytora, tylko z nieprawidłowych końców linii w pliku — najczęściej po edycji w Visual Studio lub mieszaniu Windows/Unix.
Najprostsze rozwiązanie:
✔ zaznaczyć Wyrażenie regularne ✔ użyć ^\s*\r?\n ✔ usunąć wszystkie fałszywe puste linie
Dzięki temu można w kilka sekund wyczyścić duży plik i przywrócić normalne formatowanie kodu.
Konwerter JPG → WEBP (online, bez wysyłania na serwer)
Wgraj zdjęcie JPG, ustaw jakość i pobierz zoptymalizowany plik WebP.
📁 Przeciągnij plik JPG tutaj lub kliknij
Podgląd WebP
Walidacja NIP / REGON
Wpisz numer → system automatycznie rozpozna typ i sprawdzi poprawność
Jak działa numer NIP i jak sprawdzić jego poprawność? Poradnik + Kalkulator NIP
Numer Identyfikacji Podatkowej, czyli NIP, to jeden z najważniejszych identyfikatorów podatkowych w Polsce. Wykorzystuje się go w kontaktach z urzędami, kontrahentami, bankami, księgowością oraz w dokumentach sprzedaży. W tym artykule wyjaśniamy, jak zbudowany jest numer NIP, jak działa jego weryfikacja oraz udostępniamy praktyczne narzędzie online – Kalkulator NIP.
Czym jest NIP?
NIP to dziesięciocyfrowy numer nadawany przedsiębiorcom oraz osobom prowadzącym działalność gospodarczą. Jego celem jest jednoznaczna identyfikacja podatkowa. Każda cyfra NIP-u pełni określoną rolę, a ostatnia cyfra jest cyfrą kontrolną, dzięki której można sprawdzić poprawność całego numeru.
Jak działa walidacja numeru NIP?
Poprawność NIP-u można sprawdzić za pomocą specjalnego algorytmu opartego na wagach przypisanych do pierwszych dziewięciu cyfr. Proces weryfikacji wygląda następująco:
usunięcie spacji i myślników z numeru NIP,
sprawdzenie, czy numer zawiera dokładnie 10 cyfr,
pomnożenie każdej z 9 pierwszych cyfr przez odpowiednie wagi,
obliczenie sumy i wykonanie operacji modulo 11,
porównanie wyniku z ostatnią cyfrą NIP.
Wagi używane w algorytmie NIP: 6, 5, 7, 2, 3, 4, 5, 6, 7.
Kalkulator NIP – szybka weryfikacja online
Przygotowane narzędzie pozwala nie tylko sprawdzić poprawność numeru, ale również zweryfikować, czy firma faktycznie istnieje i działa. Kalkulator automatycznie:
analizuje strukturę numeru NIP,
sprawdza cyfrę kontrolną,
komunikuje błędny format lub niepoprawny numer,
łączy się z oficjalnym API Ministerstwa Finansów (KAS),
sprawdza, czy firma jest wpisana w rejestr podatników VAT,
weryfikuje status działalności (czynny, zwolniony, niezarejestrowany),
zwraca dane z bazy MF, takie jak nazwa firmy, REGON, adres i status VAT.
Dzięki temu otrzymujesz nie tylko informację, czy numer NIP jest prawidłowy matematycznie, ale również — czy podmiot rzeczywiście funkcjonuje i figuruje w oficjalnym wykazie podatników.
Dlaczego warto sprawdzać NIP?
Poprawny numer NIP jest niezbędny w procesach księgowych, prawnych i biznesowych. Błędny lub nieistniejący NIP może powodować problemy z fakturami, rozliczeniami podatkowymi, a także opóźnienia w realizacji usług. Automatyczna weryfikacja z bazą Ministerstwa Finansów pozwala uniknąć współpracy z nieuczciwymi lub nieaktywnymi podmiotami.
Najczęstsze błędy w numerach NIP
zbyt krótki lub zbyt długi numer,
literówki podczas przepisywania,
wstawienie litery zamiast cyfry,
błędna cyfra kontrolna,
dodatkowe znaki: spacje, myślniki, kropki.
FAQ – najczęściej zadawane pytania o NIP
Czy NIP dla osoby prywatnej i firmy jest taki sam?
Tak. Zarówno osoby fizyczne, jak i przedsiębiorcy posiadają dziesięciocyfrowy numer NIP w identycznym formacie i algorytmie kontroli.
Czy NIP można zmienić?
Nie. Numer NIP jest przypisany do podatnika na stałe.
Czy NIP może zaczynać się od zera?
Tak. Algorytm walidacji pozwala na zera na dowolnej pozycji numeru.
Jak sprawdzić, czy firma jest aktywnym podatnikiem VAT?
Kalkulator korzysta bezpośrednio z oficjalnego API Ministerstwa Finansów. Po wpisaniu poprawnego NIP-u narzędzie automatycznie zweryfikuje, czy firma widnieje w rejestrze VAT oraz jaki ma status.
Podsumowanie
Numer NIP jest kluczowym identyfikatorem podatkowym i warto upewniać się, że jest poprawny przed wystawieniem faktury lub zawarciem umowy. Dzięki bezpłatnemu narzędziu online możesz szybko i wygodnie sprawdzić poprawność NIP-u, istnienie firmy oraz jej status podatkowy w oficjalnym rejestrze Ministerstwa Finansów.
Jeśli korzystasz z PrestaShop i potrzebujesz gotowego skryptu do automatycznej walidacji pola NIP w formularzu zamówienia lub rejestracji, znajdziesz go tutaj: https://pro-link.pl/walidacja-pola-nip-w-prestashop
Kalkulator PESEL
Wpisz numer → wynik pojawia się natychmiast
Wprowadź PESEL
Tylko cyfry — 11 znaków
Wynik kalkulacji nr. PESEL LIVE
Wpisz PESEL po lewej, a tutaj pojawi się pełna analiza…
Jak odczytać i zweryfikować numer PESEL? Przykład krok po kroku
Numer PESEL to jeden z najważniejszych identyfikatorów używanych w Polsce. Każda osoba mieszkająca w kraju – lub przebywająca tu na stałe – otrzymuje swoje indywidualne 11-cyfrowe oznaczenie. Choć PESEL wydaje się ciągiem przypadkowych liczb, w rzeczywistości zawiera bardzo konkretne informacje: datę urodzenia, płeć oraz specjalną cyfrę kontrolną, która decyduje o jego poprawności.
W tym artykule pokażę, jak samodzielnie odczytać i zweryfikować numer PESEL, na przykładzie numeru 81101254123.
Z czego składa się numer PESEL?
PESEL składa się z 11 cyfr, które pełnią konkretne funkcje:
1–6 cyfra – data urodzenia
7–10 cyfra – indywidualny numer serii (zawiera płeć)
11 cyfra – cyfra kontrolna, która potwierdza poprawność całego numeru
Na pierwszy rzut oka PESEL może wyglądać skomplikowanie, ale jego struktura jest bardzo logiczna.
Rozszyfrowanie PESEL 81101254123
Przejdźmy teraz do analizy konkretnego numeru. PESEL: 81 10 12 54123
1. Rok urodzenia – cyfry 1–2
81 → 1981 rok
2. Miesiąc urodzenia – cyfry 3–4
10 → październik (Warto wiedzieć: system dodaje 20, 40, 60 lub 80 dla innych stuleci. Tu brak dodatku = lata 1900–1999) Cyfry 3–4 w numerze PESEL odpowiadają za miesiąc urodzenia, ale mogą zawierać modyfikację, która określa stulecie. Dlatego miesiąc nie zawsze mieści się w zakresie 01–12 — czasem wygląda jak 20-32, 40-52, 60-72 czy 80-92. To nie są tygodnie ani błędy, tylko specjalny system kodowania daty.
✔ Jak działa kodowanie miesiąca?
Stulecie
Dodatek
Zakres zapisanych miesięcy
Jak odczytać?
1900–1999
+0
01–12
klasyczne miesiące
2000–2099
+20
21–32
miesiąc = liczba − 20
2100–2199
+40
41–52
miesiąc = liczba − 40
2200–2299
+60
61–72
miesiąc = liczba − 60
1800–1899
+80
81–92
miesiąc = liczba − 80
3. Dzień urodzenia – cyfry 5–6
12 → 12 dzień miesiąca
Data urodzenia z PESEL: 12.10.1981
Określanie płci na podstawie PESEL
Cyfra płci to 10. cyfra PESEL (w naszym przypadku: 2).
cyfry parzyste → kobieta
cyfry nieparzyste → mężczyzna
PESEL wskazuje na kobietę
Walidacja cyfry kontrolnej – czy PESEL jest poprawny?
Ostatnia, 11. cyfra (w przykładzie: 3) to cyfra kontrolna. Oblicza się ją według specjalnego algorytmu z użyciem wag:
1, 3, 7, 9, 1, 3, 7, 9, 1, 3
Każdą z pierwszych 10 cyfr PESEL mnożymy przez odpowiednią wagę i sumujemy wyniki. Następnie:
liczymy sumę kontrolną,
bierzemy ostatnią cyfrę tej sumy,
odejmujemy ją od 10,
wynik mod 10 to cyfra kontrolna.
Wynik dla numeru 81101254123:
✔ Obliczenia wykazały, że prawidłowa cyfra kontrolna powinna wynosić 7 ❌ W numerze jest 3
PESEL 81101254123 jest niepoprawny.
Podsumowanie
Numer PESEL można bardzo łatwo rozszyfrować, jeśli zna się zasady jego budowy. Z naszego przykładu wynika, że:
data urodzenia: 12 października 1981
płeć: kobieta
cyfra kontrolna: niepoprawna
cały PESEL: nieprawidłowy
Jak zmienić widok wiadomości w Thunderbird?
Klienci pocztowi typu desktop wciąż mają sporą przewagę nad webmailami – są szybsze, wygodniejsze i dają większą kontrolę nad wyglądem skrzynki. Jednym z najpopularniejszych programów tego typu jest Mozilla Thunderbird, który pozwala dopasować układ paneli i listy wiadomości do sposobu pracy użytkownika. W tym artykule pokazujemy, jak działają najważniejsze układy oraz jak przełączyć widok na tabelę.
Widok pionowy (Vertical View)
To obecnie najczęściej używany układ w Thunderbirdzie.
Lista wiadomości znajduje się po lewej stronie okna.
Podgląd treści wiadomości wyświetlany jest po prawej stronie.
Widok świetnie sprawdza się na szerokich monitorach (FullHD, 2K, 4K).
Kiedy warto użyć? Widok pionowy polecany jest osobom, które pracują z dużą liczbą maili i mają szeroki ekran – np. w firmach, działach IT, helpdesku czy obsłudze klienta.
Widok szeroki (Wide View)
Widok szeroki to kompromis między klasycznym a pionowym układem.
Panel folderów znajduje się po lewej stronie.
Lista wiadomości wyświetlana jest na górze, na całej szerokości okna.
Podgląd wiadomości znajduje się poniżej listy.
Kiedy warto użyć? Ten układ dobrze sprawdza się na laptopach oraz ekranach o mniejszej szerokości, gdzie trudno wygospodarować dużo miejsca na podgląd po prawej stronie.
Widok klasyczny (Classic View)
Widok klasyczny przypomina układ znany z dawnych klientów pocztowych, takich jak Outlook Express czy Windows Mail.
Foldery po lewej stronie okna.
Lista wiadomości po prawej, w górnej części.
Podgląd wiadomości na dole, pod listą.
Zalety:
czytelny, tradycyjny układ, który nie zaskoczy użytkowników przyzwyczajonych do starszych programów,
wygodne przeglądanie dużej liczby nagłówków wiadomości jedna pod drugą.
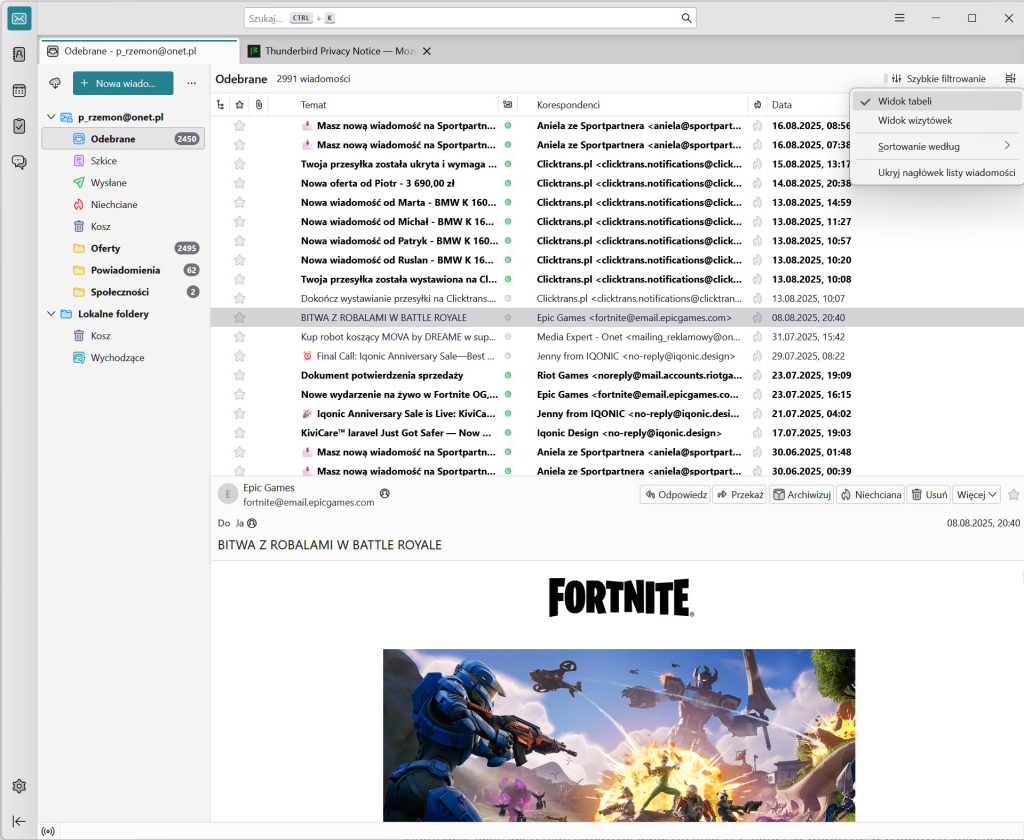
Widok tabeli (Table View) – maksymalnie czytelna lista wiadomości
Widok tabelaryczny pokazuje wiadomości w formie przejrzystej tabeli – podobnie jak w arkuszu kalkulacyjnym:
każda wiadomość to jeden wiersz,
informacje takie jak temat, nadawca, data, rozmiar czy status są widoczne w osobnych kolumnach,
kolumny można dowolnie włączać, wyłączać i zmieniać ich kolejność.
Przykład widoku tabelarycznego listy wiadomości w Thunderbirdzie.
Jak włączyć widok tabelaryczny w Thunderbirdzie?
Metoda 1 – menu Widok
Uruchom program Mozilla Thunderbird.
Przejdź do górnego menu i wybierz: Widok → Układ.
Zaznacz opcję Widok tabelaryczny (Table View).
Po wybraniu tej opcji lista wiadomości zmieni się na klasyczny widok z kolumnami – tematem, nadawcą, datą i innymi parametrami.
Metoda 2 – ikona zmiany układu
Nad listą wiadomości (zwykle po prawej stronie paska narzędzi) znajdź ikonę zmiany układu widoku.
Kliknij ikonę i z rozwijanego menu wybierz Table lub Widok tabelaryczny.
Jak przełączać widoki: pionowy, szeroki i klasyczny?
Zmiana układu paneli w Thunderbirdzie jest bardzo prosta i dostępna z jednego miejsca:
Otwórz Thunderbirda.
Z górnego menu wybierz: Widok → Układ.
Następnie wybierz interesujący Cię tryb:
Pionowy (Vertical View),
Szeroki (Wide View),
Klasyczny (Classic View).
Zmiana widoku działa od razu – bez restartu programu czy dodatkowych ustawień.
Podsumowanie
Thunderbird daje dużą swobodę w dopasowaniu wyglądu skrzynki pocztowej do preferencji użytkownika. W kilka sekund możesz przełączyć się między różnymi układami:
Widok pionowy – idealny na szerokie monitory i intensywną pracę z mailami.
Widok szeroki – wygodny na laptopach i ekranach o mniejszej szerokości.
Widok klasyczny – znany, tradycyjny układ z podglądem na dole.
Widok tabelaryczny – maksymalnie przejrzysta lista wiadomości w formie tabeli.
Dobrze dobrany widok znacząco przyspiesza pracę z pocztą, poprawia czytelność i pomaga utrzymać porządek w skrzynce odbiorczej – zarówno w domu, jak i w firmie.